Downstream resiliency ensures that a component can continue to function correctly even if the components it relies on experience issues.
𝗧𝗶𝗺𝗲𝗼𝘂𝘁
Before we start, let’s answer the simple question: "Why timeout?".
A successful response, even if it takes time, is better than a timeout error. Hmm… not always, it depends.
When a network call is made, it’s best practice to configure a timeout. If the call is made without a timeout, there is a chance it will never return. Network calls that don’t return lead to resource leaks.
Modern HTTP clients such as Java, .NET etc do a better job and usually, come with default timeouts. For example, .NET Core HttpClient has a default timeout of 100 seconds. However, some HTTP clients, like Go, do not have a default timeout for network requests. In such cases, it is a best practice to explicitly configure a timeout.
How to configure timeout and not breach the SLA?
Option 1: Share Your Time Budget
Divide your SLA between services, e.g., 500ms for Order Service and 500ms for Payment Service. This prevents SLA breaches but may cause false positive timeouts.
Option 2: Use a TimeLimiter
Wrap calls in a time limiter, setting a shared max timeout (e.g., 1s) while allowing flexibility (e.g., 700ms per service) to handle varying response times efficiently.
How do we determine a good timeout duration?
One way is to base it on the desired false timeout rate. For example, if 0.1% of downstream requests can timeout, configure the timeout based on the 99.9th percentile of response time.
Good monitoring tracks the entire lifecycle of a network call. Measure integration points carefully. This helps with debugging production issues.
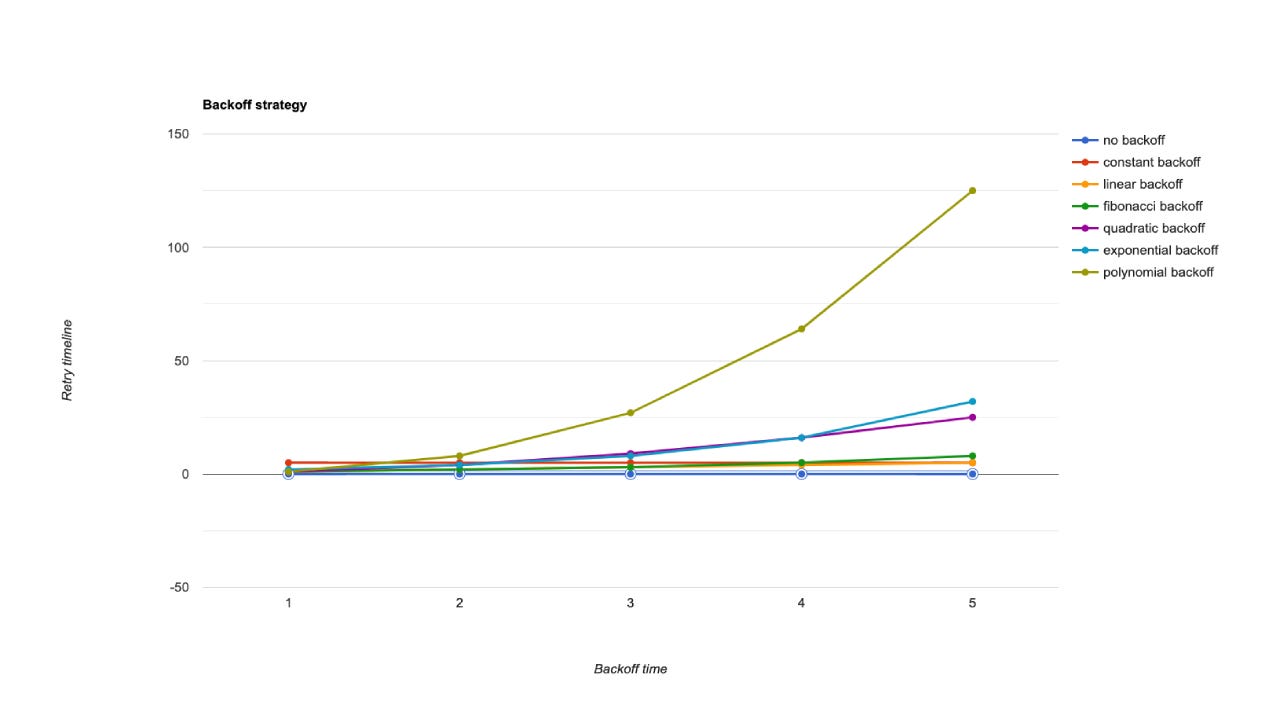
𝗥𝗲𝘁𝗿𝘆 𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝗶𝗲𝘀
When a network request fails or times out, the client has two options: fail fast or retry the request. If the failure is temporary, retrying with backoff can resolve the issue. However, if the downstream service is overwhelmed, immediate retries can worsen the problem. To prevent this, retries should be delayed with progressively increasing intervals until either a maximum retry limit is reached or sufficient time has passed.
This approach incorporates techniques such as Exponential Backoff, Cap, Random Jitter, and Retry Queue, ensuring the system remains resilient while avoiding additional strain on the downstream service.
𝗘𝘅𝗽𝗼𝗻𝗲𝗻𝘁𝗶𝗮𝗹 𝗕𝗮𝗰𝗸𝗼𝗳𝗳
Exponential backoff is a technique where the retry delay increases exponentially after each failure.
backoff = backOffMin * (backOffFactor ^ attempt)
For an initial backoff of 2 seconds and a backoff factor of 2:
1st retry: 2×2^1=2 seconds
2nd retry: 2×2^2=4 seconds
3rd retry: 2×2^3=8 seconds
This means that after each failed attempt, the time to wait before retrying increases exponentially. Exponential backoff can cause multiple clients to retry simultaneously, leading to load spikes on the downstream service. To solve this, we can limits the maximum retry delay to prevent excessive waiting times.
𝗖𝗮𝗽𝗽𝗲𝗱 𝗘𝘅𝗽𝗼𝗻𝗲𝗻𝘁𝗶𝗮𝗹 𝗕𝗮𝗰𝗸𝗼𝗳𝗳
Capped exponential backoff builds upon exponential backoff by introducing a maximum limit (cap) for the retry delay. This prevents the delay from growing indefinitely while ensuring retries happen within a reasonable timeframe.
backoff = backOffMin * (backOffFactor ^ attempt)
However, the cap limits the maximum delay. For an initial backoff of 2 seconds, a backoff factor of 2, and a cap of 8 seconds:
1st retry: 2×2^1=2 seconds
2nd retry: 2×2^2=4 seconds
3rd retry: min(2×2^3, 8)=8 seconds (capped)
Capping the delay ensures retries don't extend indefinitely, striking a balance between efficiency and resilience.
𝗥𝗮𝗻𝗱𝗼𝗺 𝗝𝗶𝘁𝘁𝗲𝗿 𝘄𝗶𝘁𝗵 𝗖𝗮𝗽𝗽𝗲𝗱 𝗘𝘅𝗽𝗼𝗻𝗲𝗻𝘁𝗶𝗮𝗹 𝗕𝗮𝗰𝗸𝗼𝗳𝗳
This method enhances capped exponential backoff by adding randomness to the delay, preventing synchronized retries and reducing the risk of traffic spikes. Random jitter spreads out retry attempts over time, improving system stability.
For an initial backoff of 2 seconds, a backoff factor of 2, and a cap of 8 seconds:
1st retry: Random value between 0 and 2×2^1=4 seconds
2nd retry: Random value between 0 and 2×2^2=8 seconds
3rd retry: Random value between 0 and 2×2^3=8 seconds (capped)
The addition of randomness avoids "retry storms," where multiple clients retry at the same time, and spreads out load more evenly to protect the downstream service.
𝗥𝗲𝘁𝗿𝘆 𝗔𝗺𝗽𝗹𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻
Suppose a user request goes through a chain: the client calls Your Awesome Service, which calls Order Service, which then calls Payment Service. If the request from Order Service to Payment Service fails, should Order Service retry? Retrying could delay Your Awesome Service’s response, risking its timeout. If Your Awesome Service retries, the client might timeout too, amplifying retries across the chain. This can overload deeper services like Payment Service. For long chains, retrying at one level and failing fast elsewhere is often better.
Figure: Retry Amplification
𝗙𝗮𝗹𝗹𝗯𝗮𝗰𝗸 𝗣𝗹𝗮𝗻
Fallback plans act as a backup when retries fail. Imagine a courier who can’t deliver your package after trying once. Instead of repeatedly attempting the same thing, they switch to a "Plan B"—like leaving the package in front of door, or at a nearby kiosk or post office. Similarly, in systems, this means using an alternative option, such as cached data or another provider, when the primary service isn’t working. The system then notifies users or logs the change, just like the courier leaving you a note or sending a text. This way, resources aren't wasted on endless retries, and the system remains resilient by relying on a practical backup solution.
When a downstream service fails persistently, retries slow down the caller and can spread slowness system-wide. A circuit breaker detects such failures, blocks requests to avoid slowdowns, and fails fast instead. It has three states: closed (passes calls, tracks failures), open (blocks calls), and half-open (tests recovery).
Figure: Circuit breaker state machine
If failures exceed a threshold, it opens; after a delay, it tests in half-open mode. Success closes it; failure reopens it. This protects the system, enabling graceful degradation for non-critical dependencies. Timing and thresholds depend on context and past data.
𝗖𝗼𝗻𝗰𝗹𝘂𝘀𝗶𝗼𝗻
Downstream resiliency is a critical aspect of Resiliency Engineering, ensuring components can adapt and recover gracefully from failures in dependent systems. By implementing effective strategies, systems can remain robust and reliable, even in the face of unforeseen disruptions.